强化学习
2025/11/24大约 1 分钟
强化学习
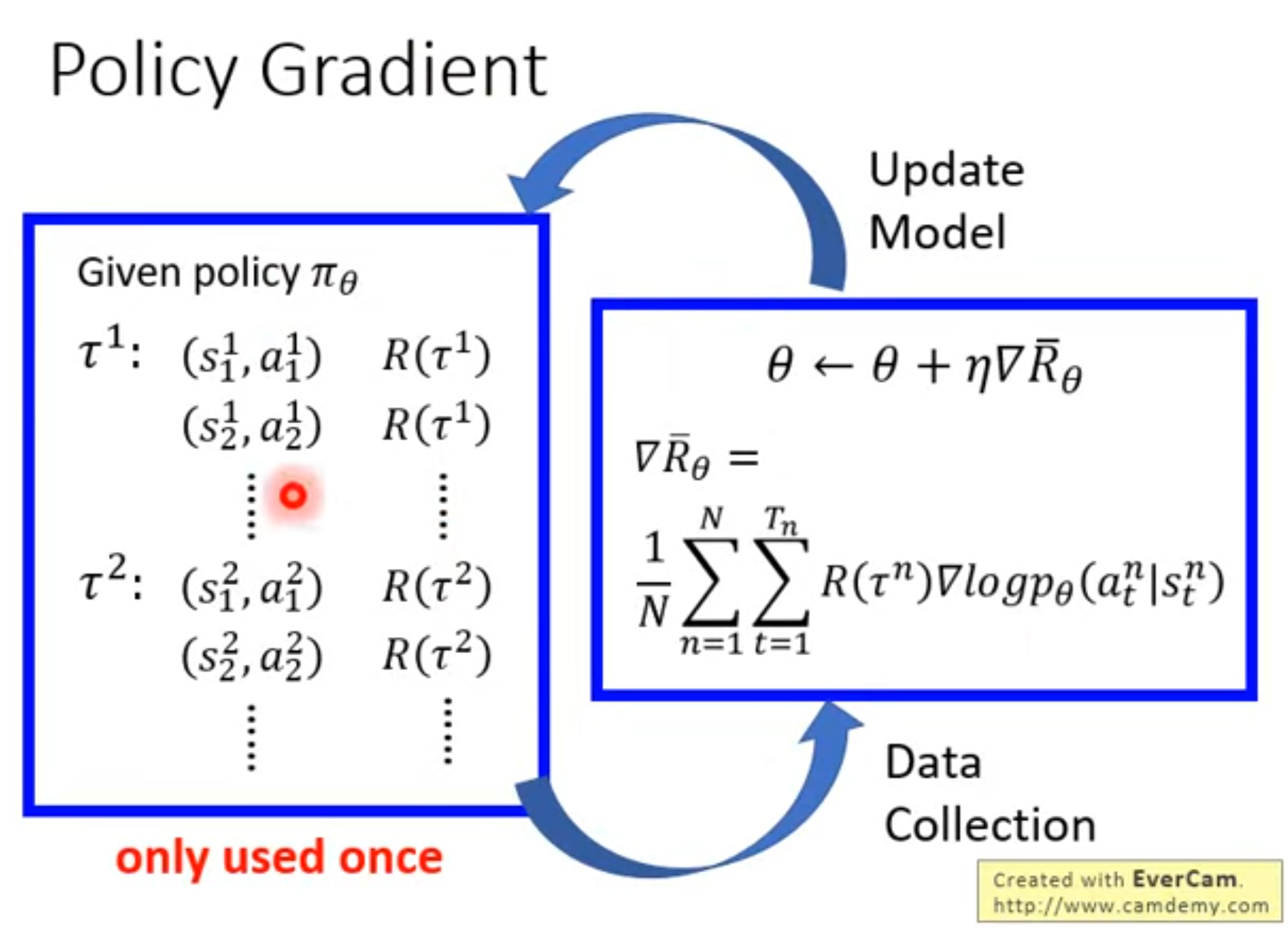
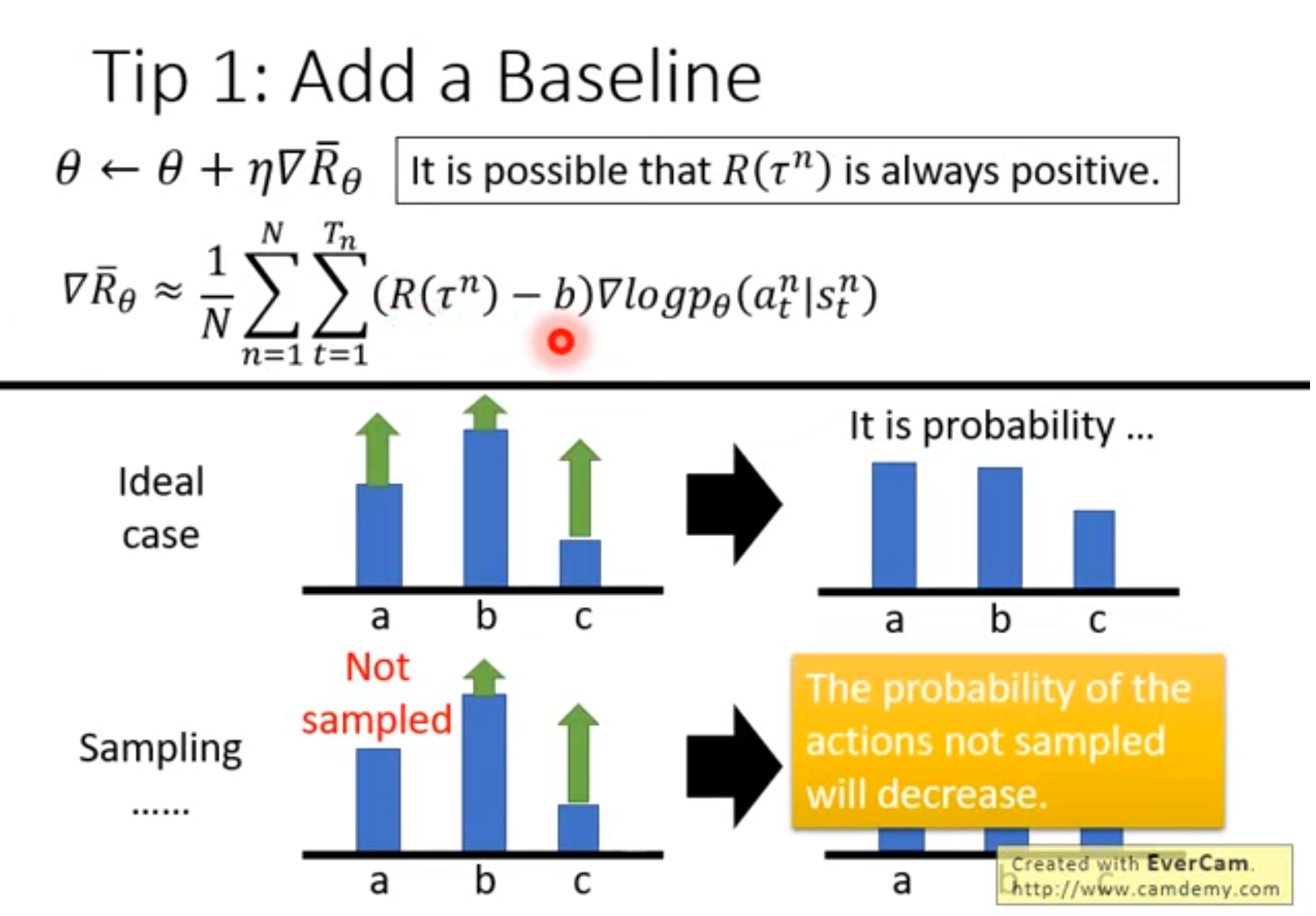
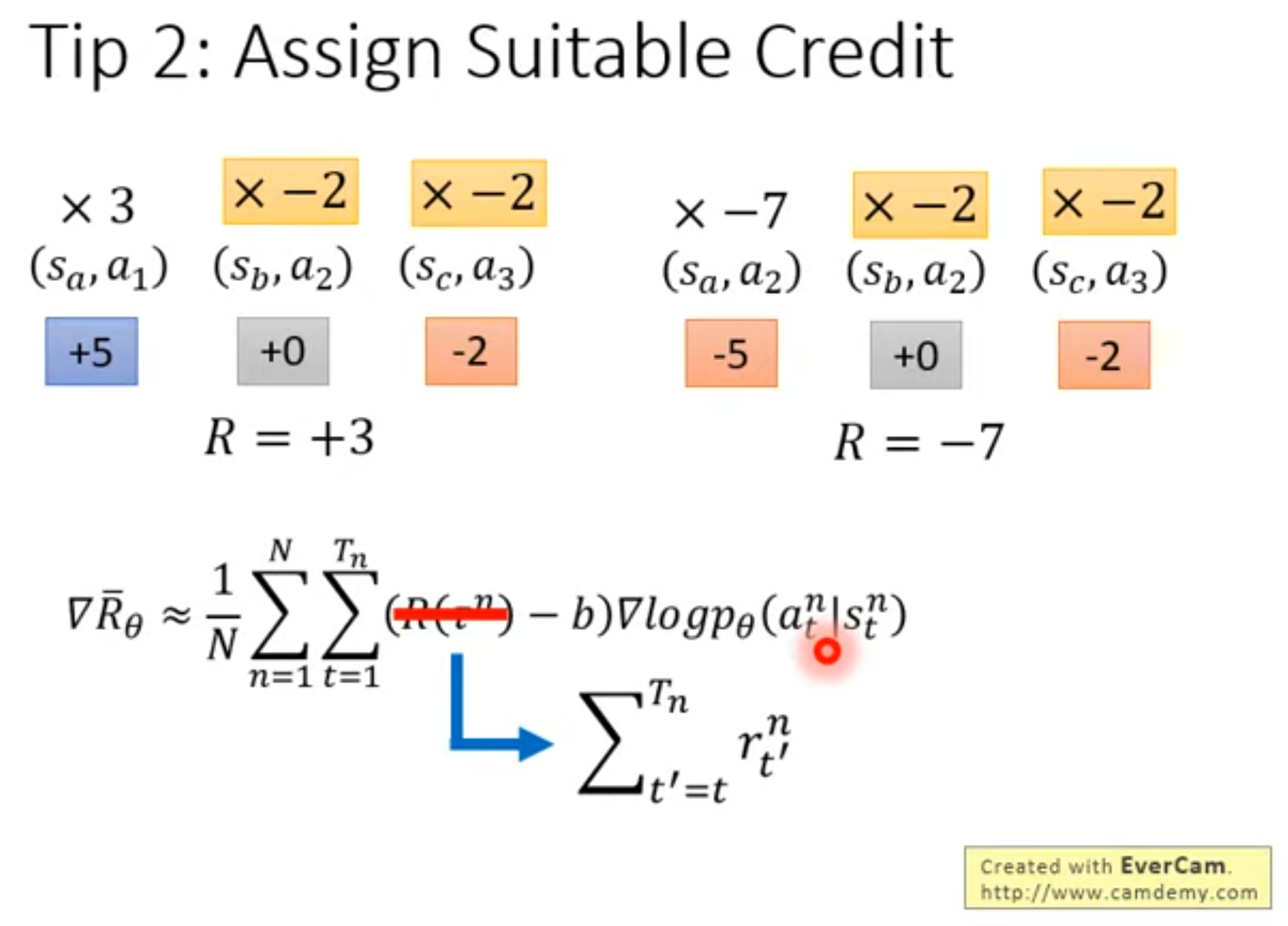
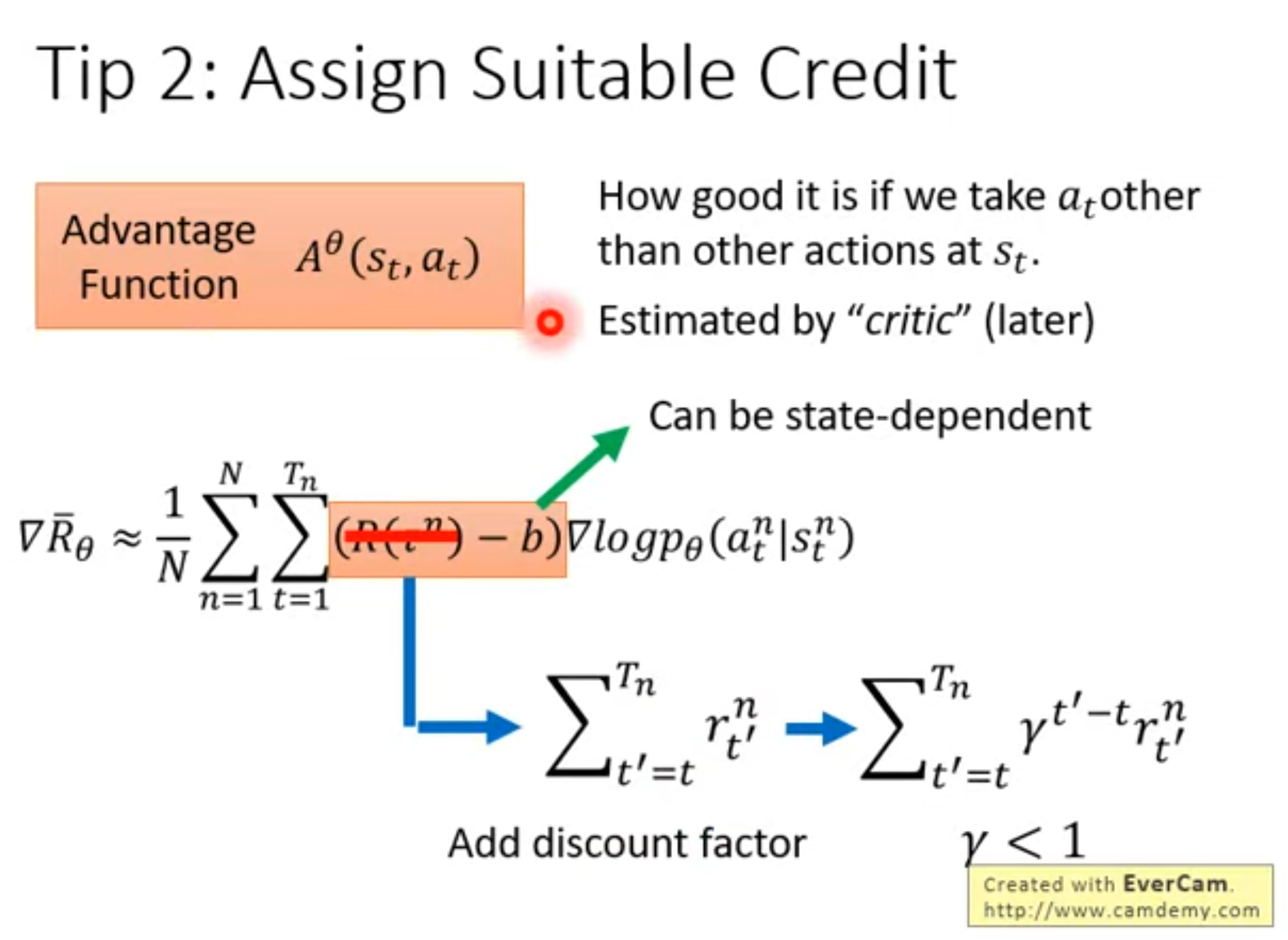
Policy Gradient
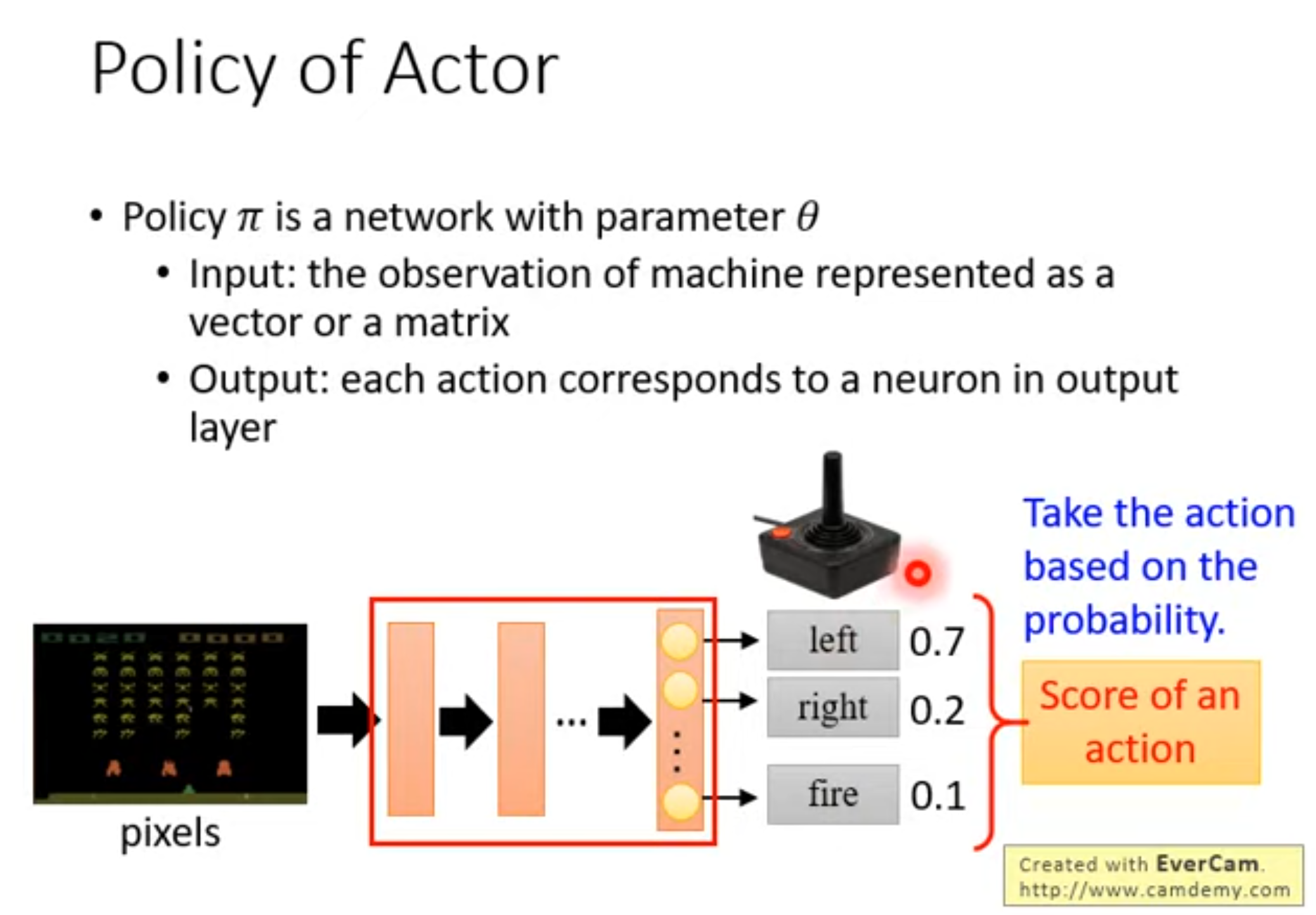
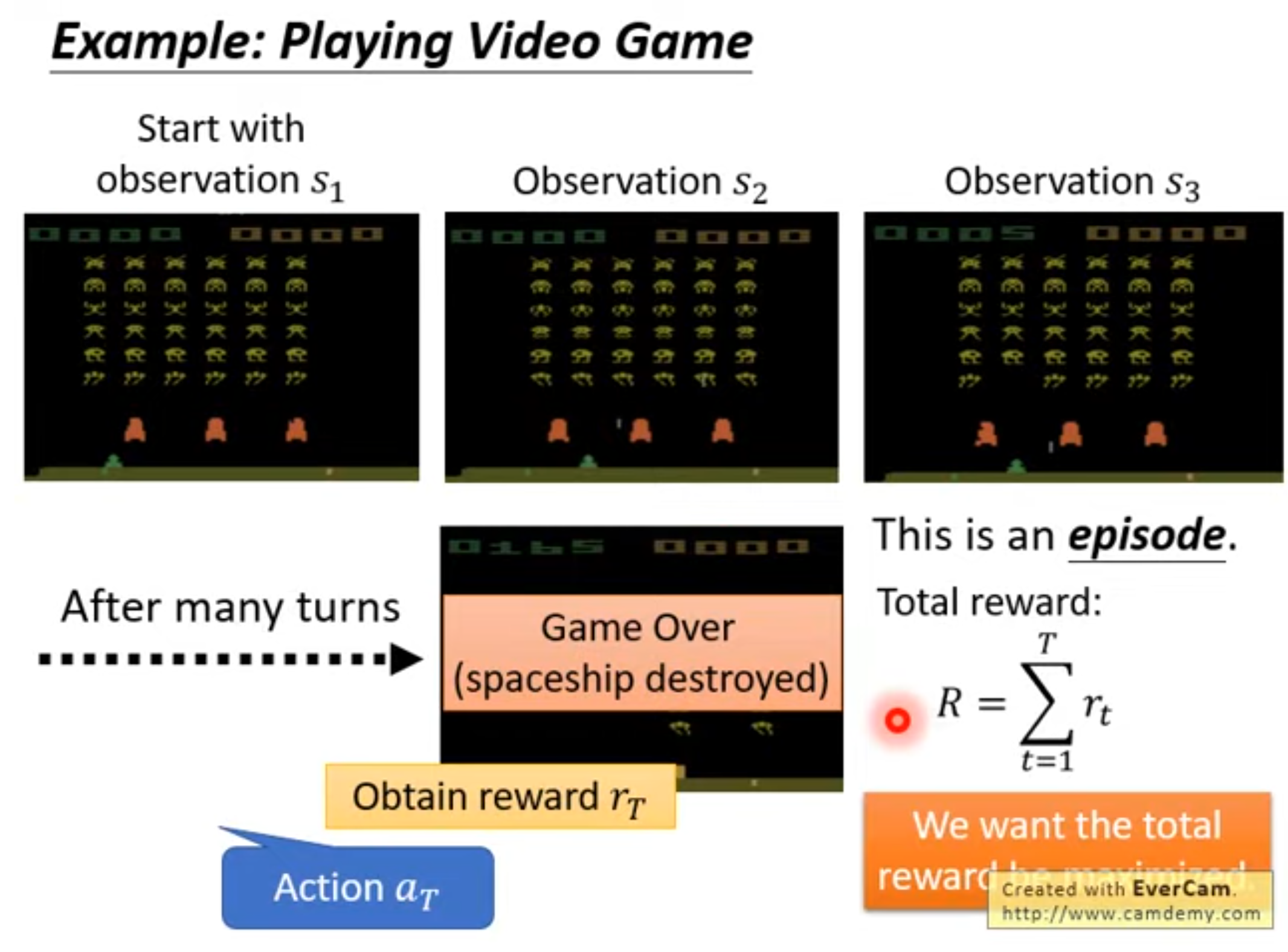
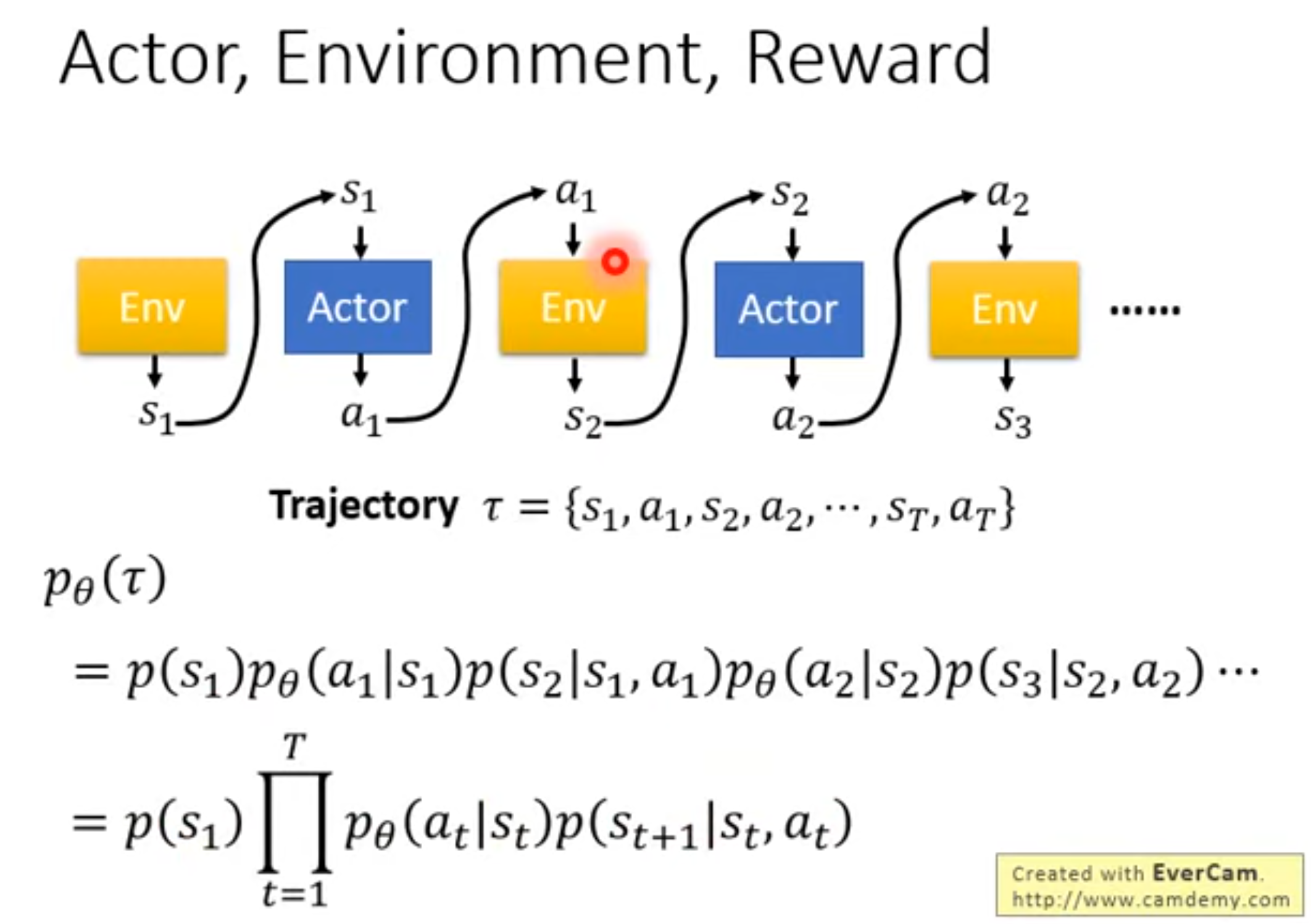
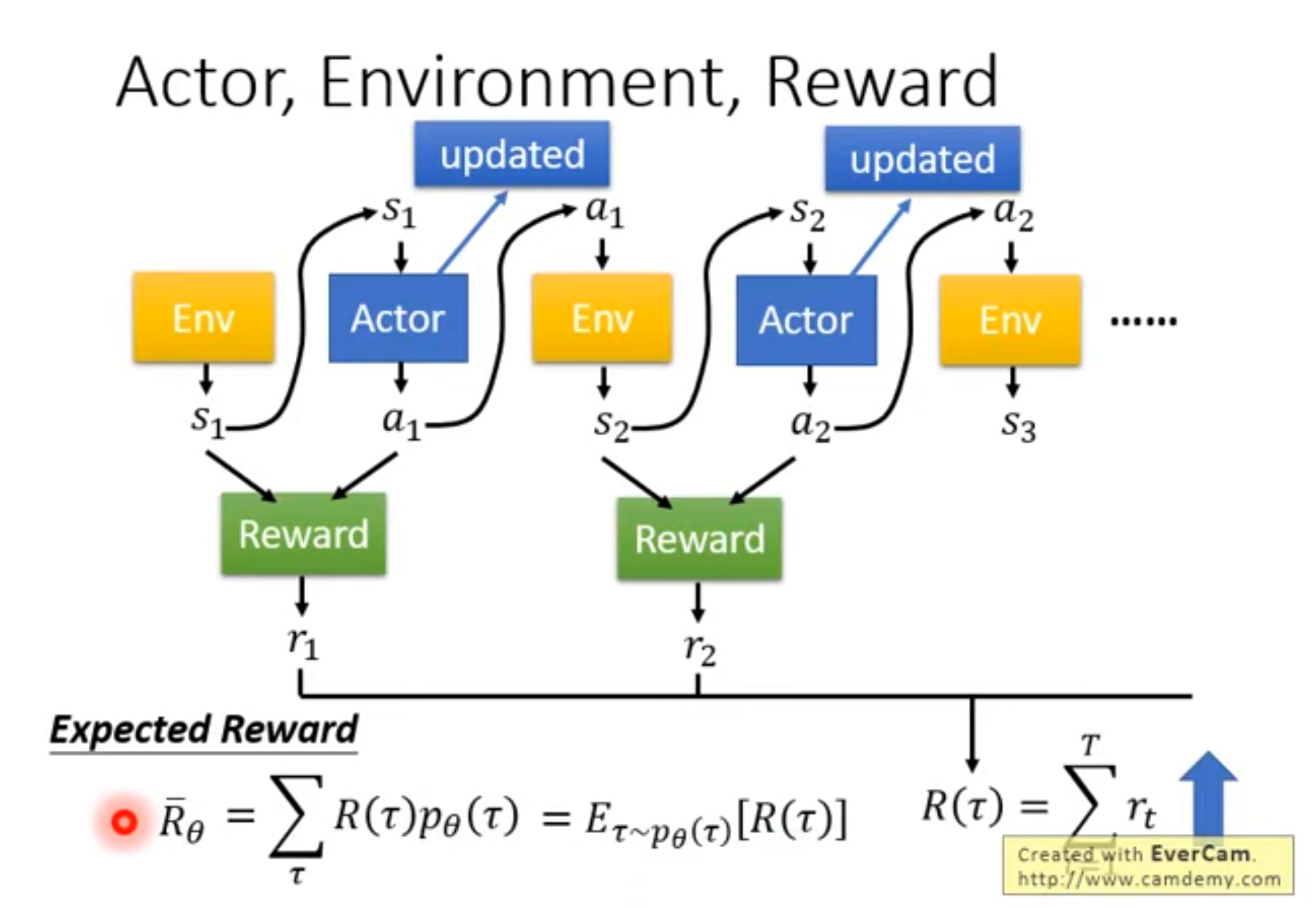


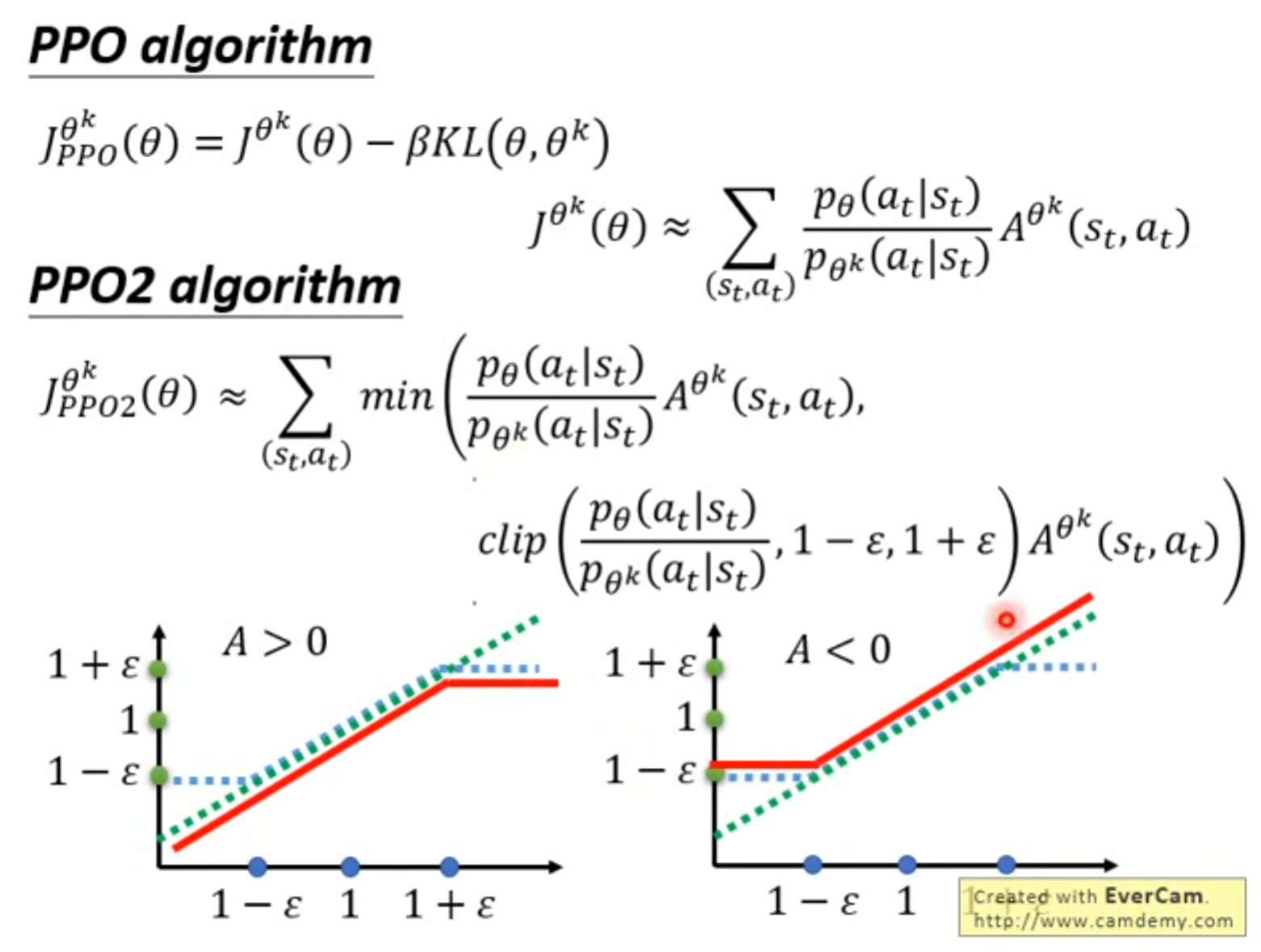
PPO(Proximal Policy Optimization)
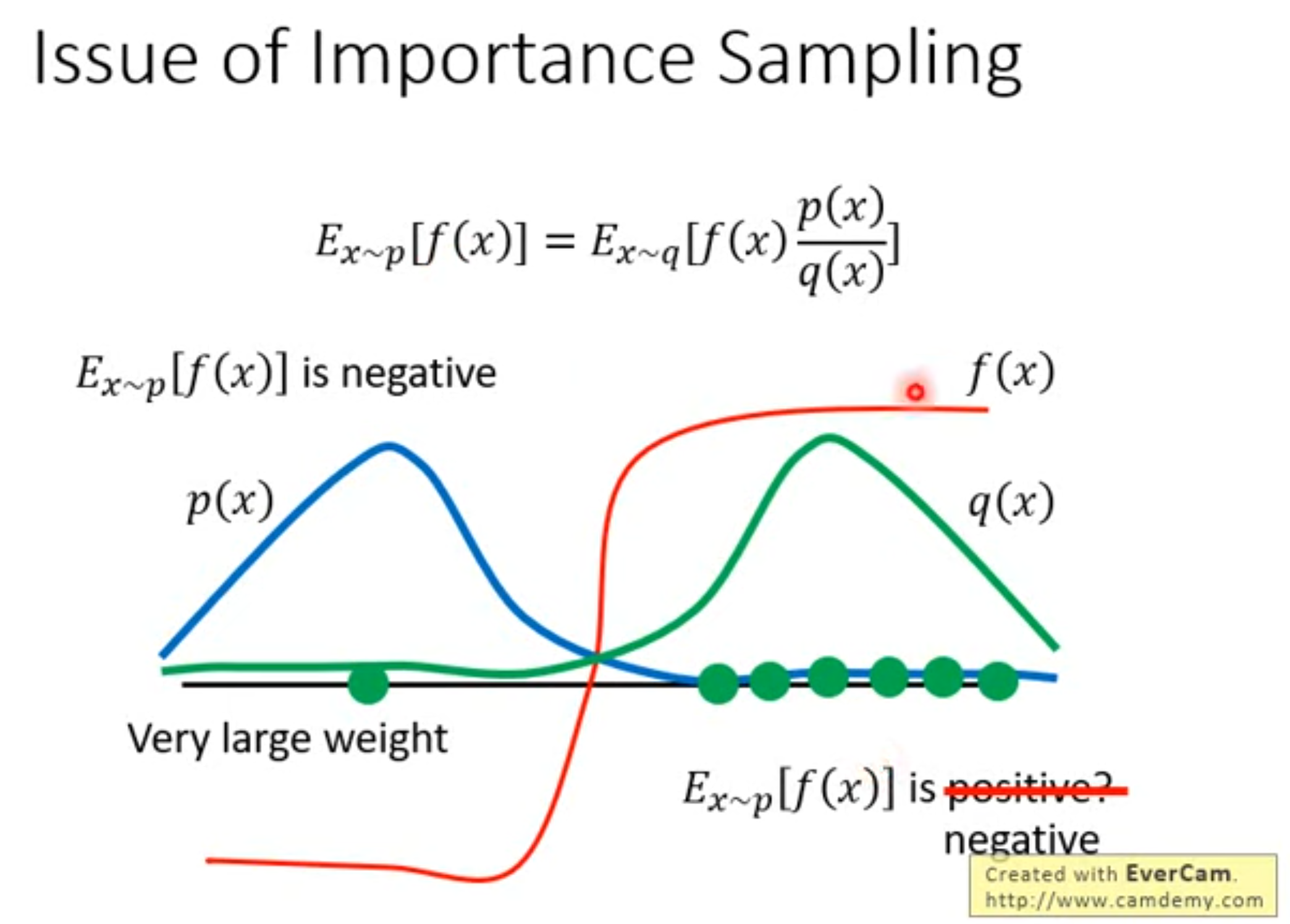
:::detials On-plolicy v.s. Off-policy
On-plolicy: 当前训练的agent与最终和环境互动的agent为同一个称为~
- on-policy在理论上更"干净",因为更新的目标和采样分布一致,使得训练更稳定,对于随机策略(如高斯)自然契合
- 样本效率低,需要持续和环境互动,旧数据很快"过期"成本高
Off-plolicy: 当前训练的agent与最终和环境互动的agent不为同一个称为~
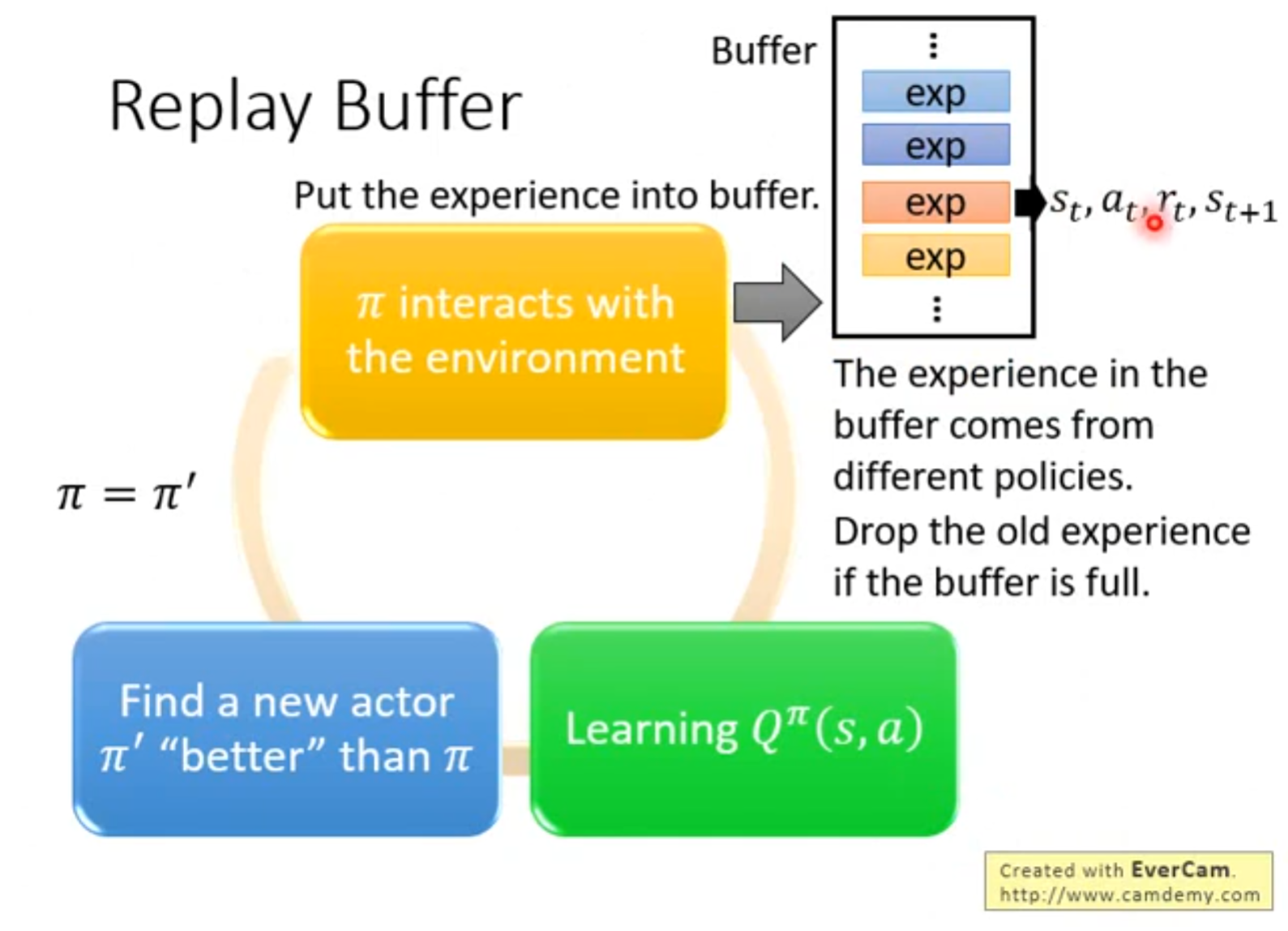
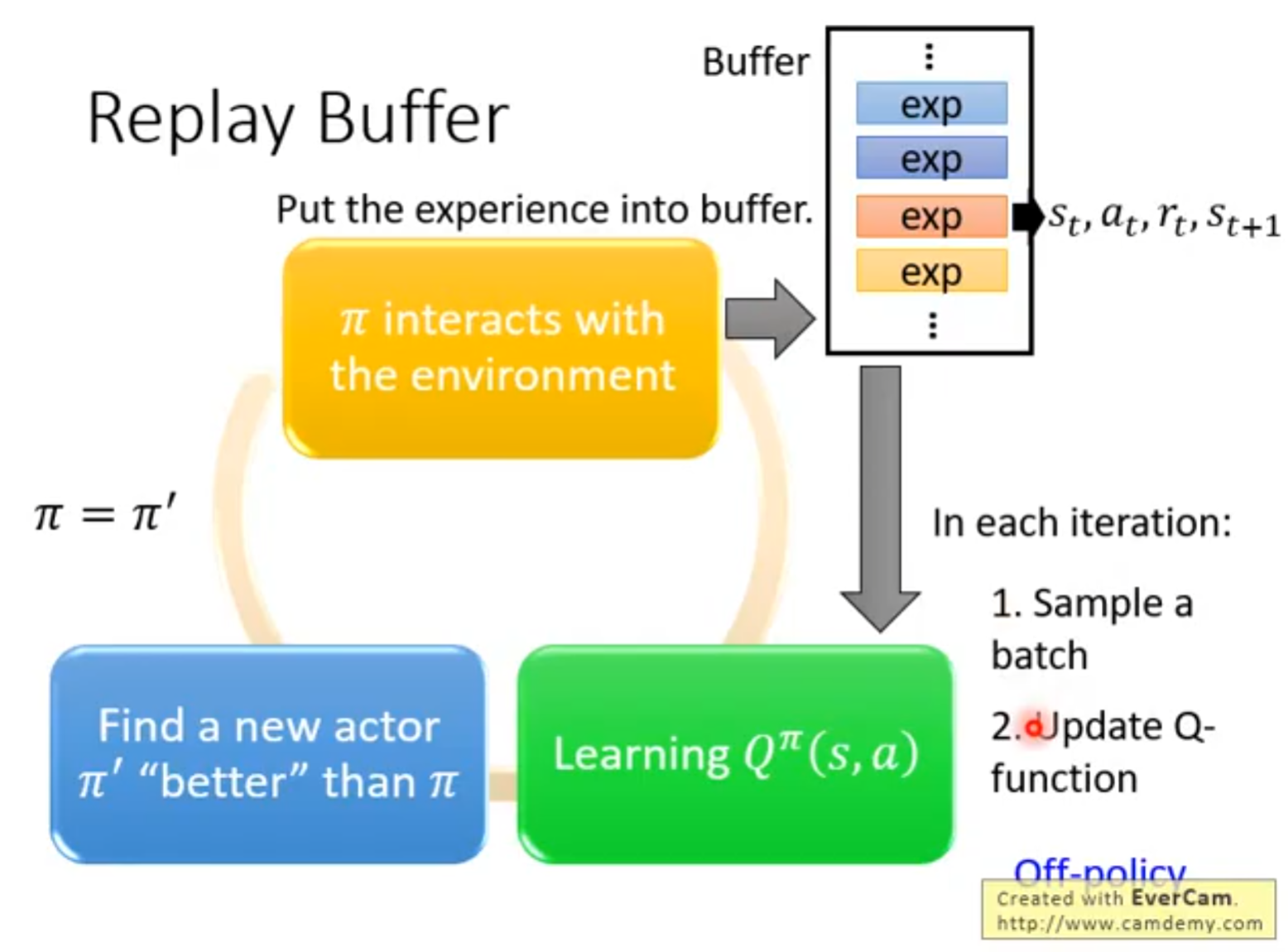
样本效率高,能够利用经验回放反复利用旧数据,能够用任意行为策略探索,同时学习更优的目标策略
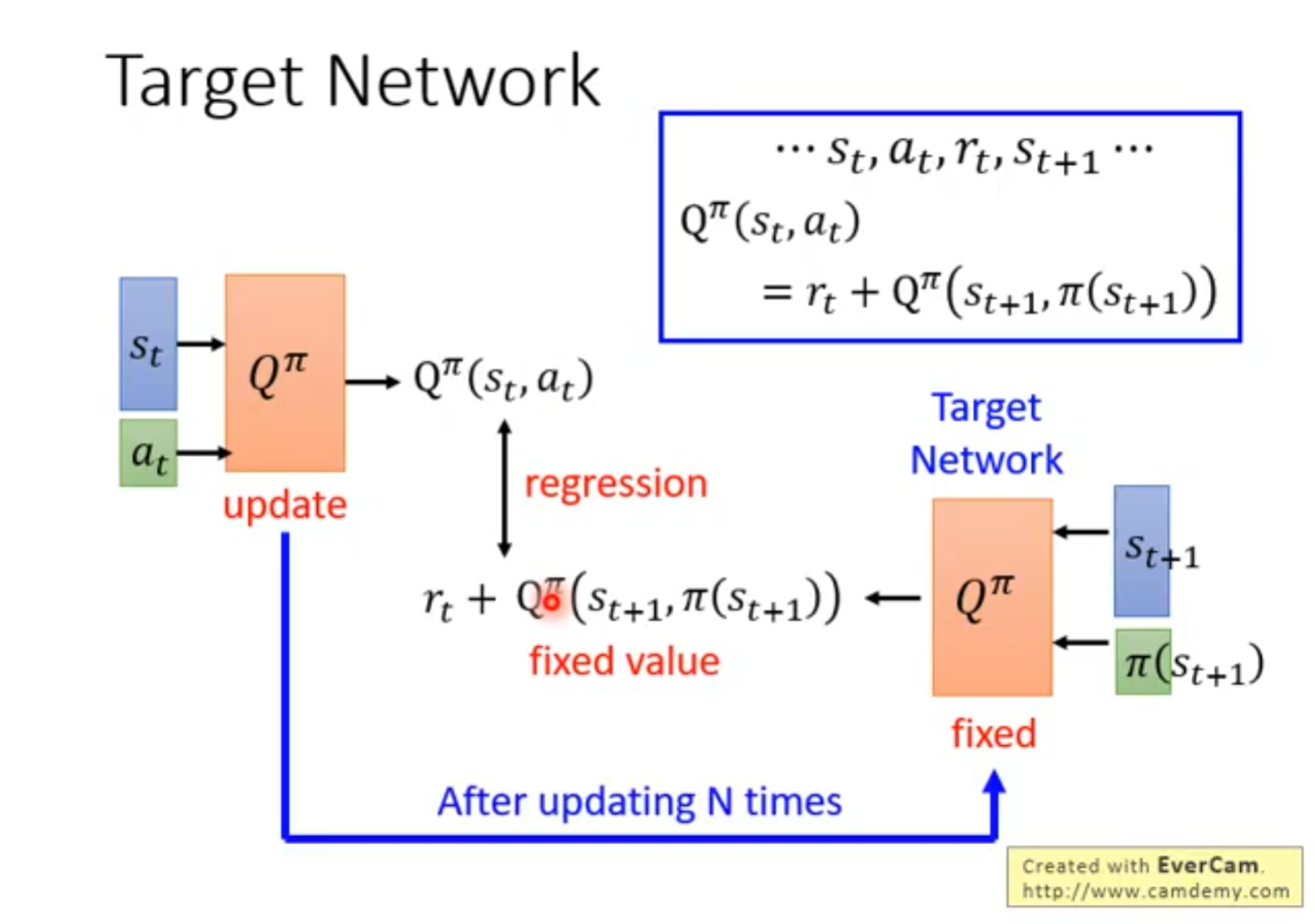
训练不稳地,容易出现"分布偏移"。往往需要矫正机制,例如重要性采样,target network,replay buffer等
:::






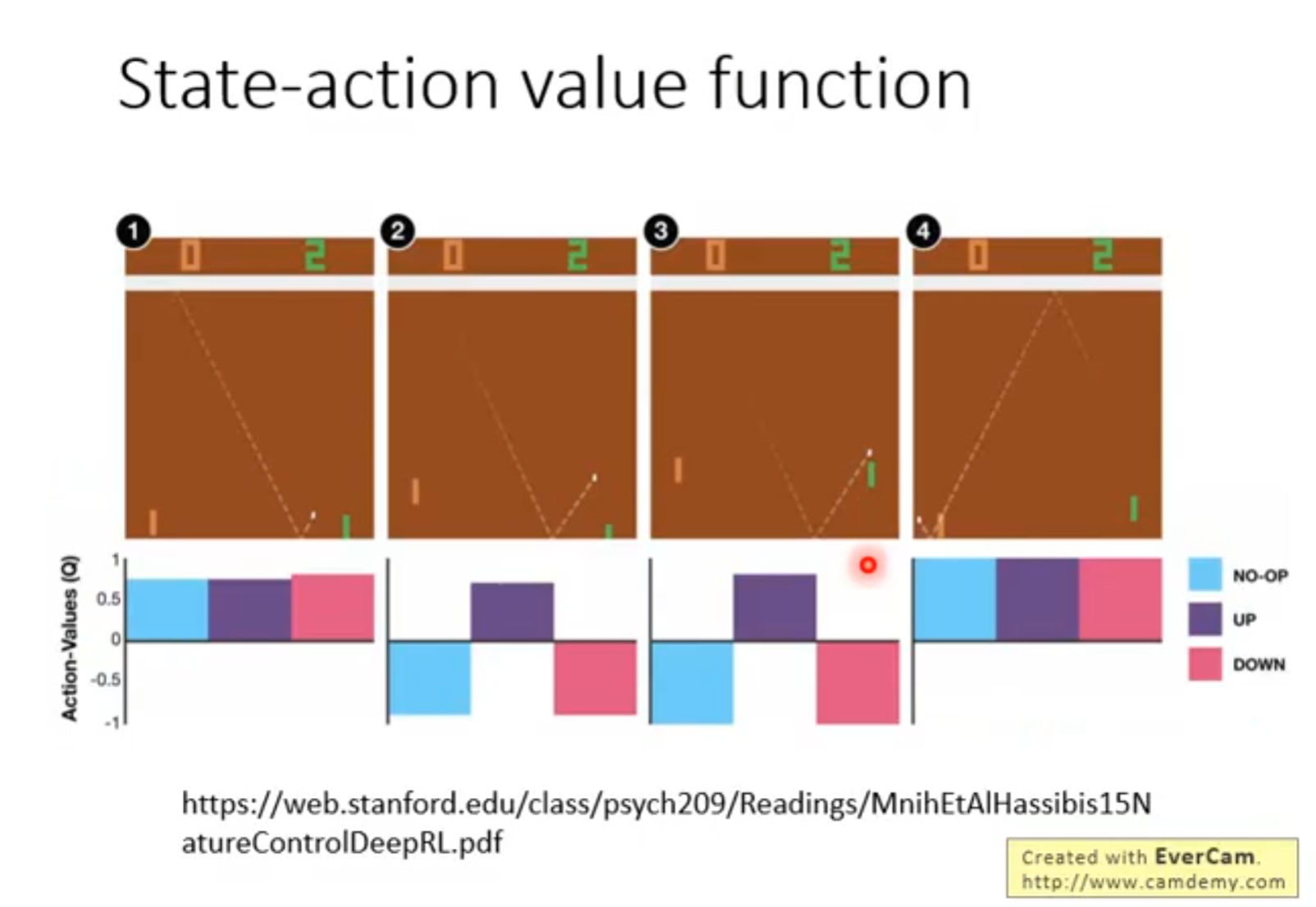
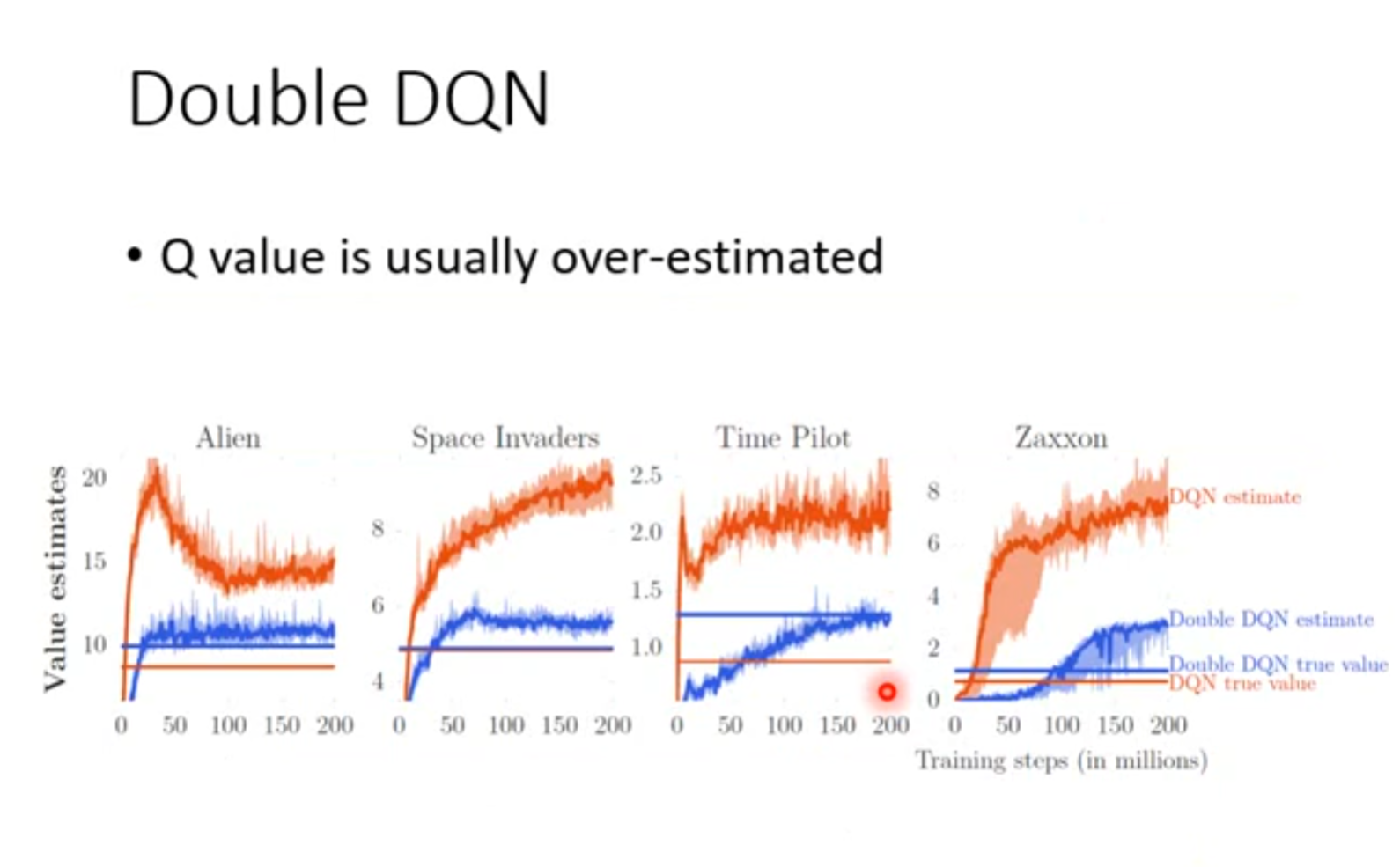
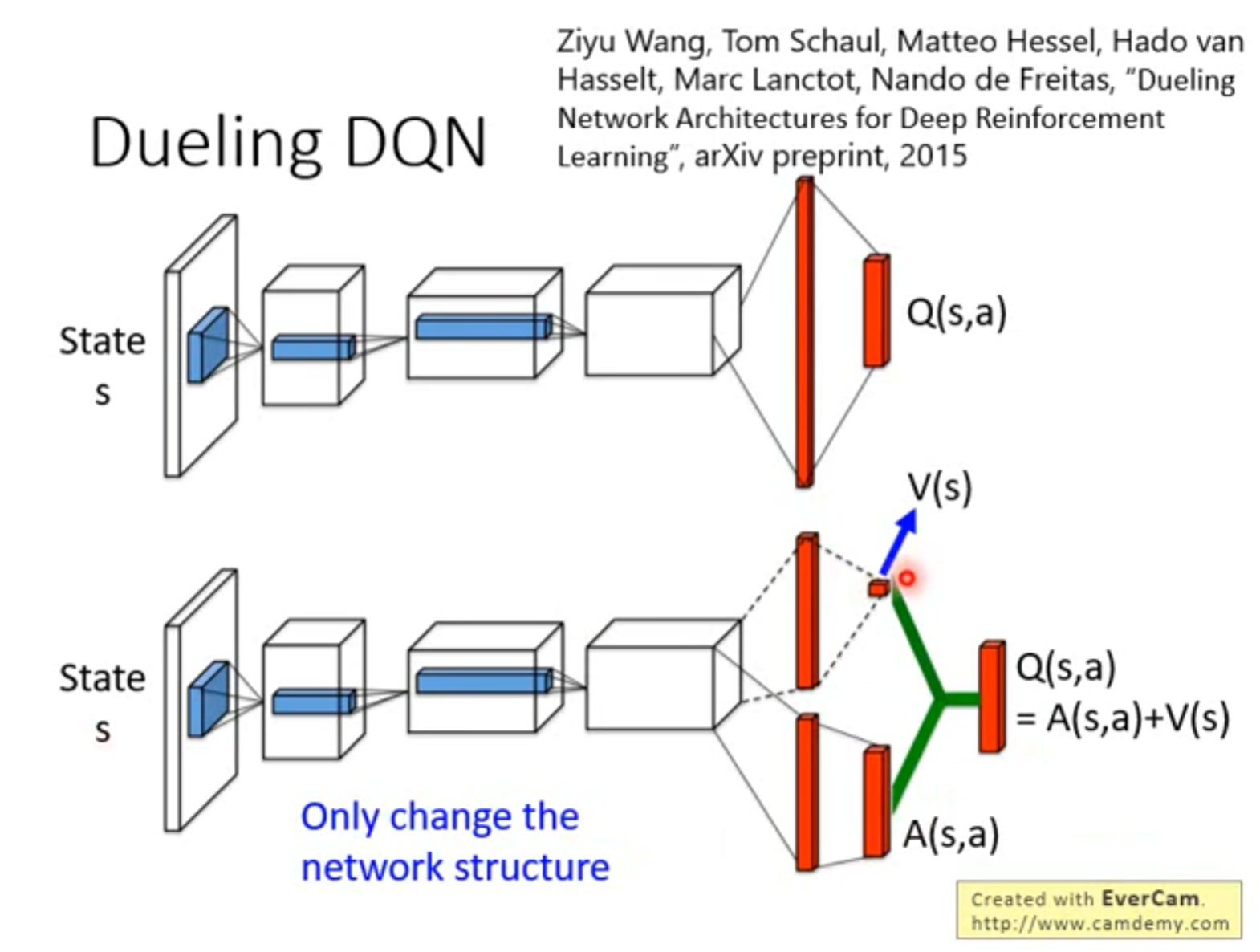
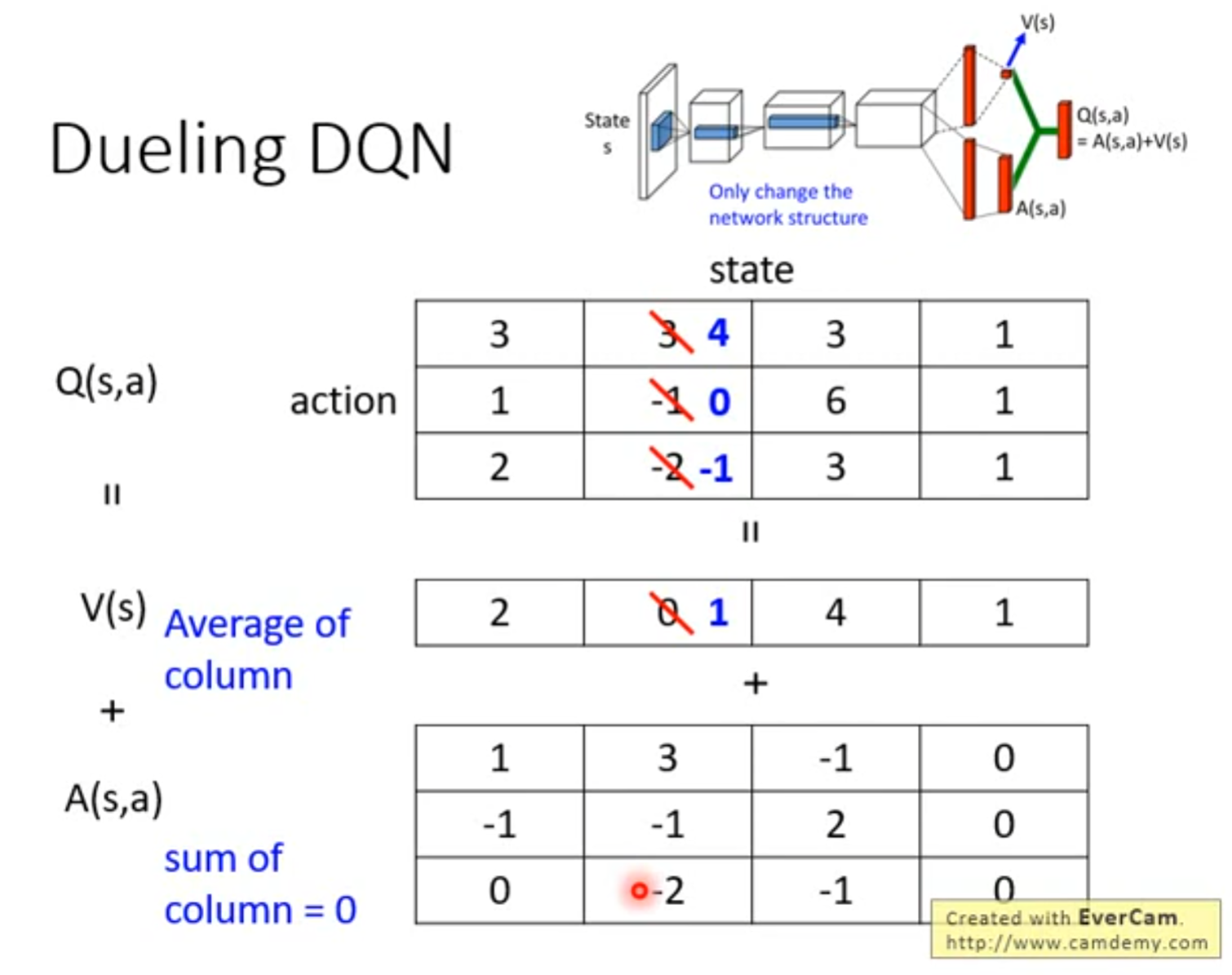
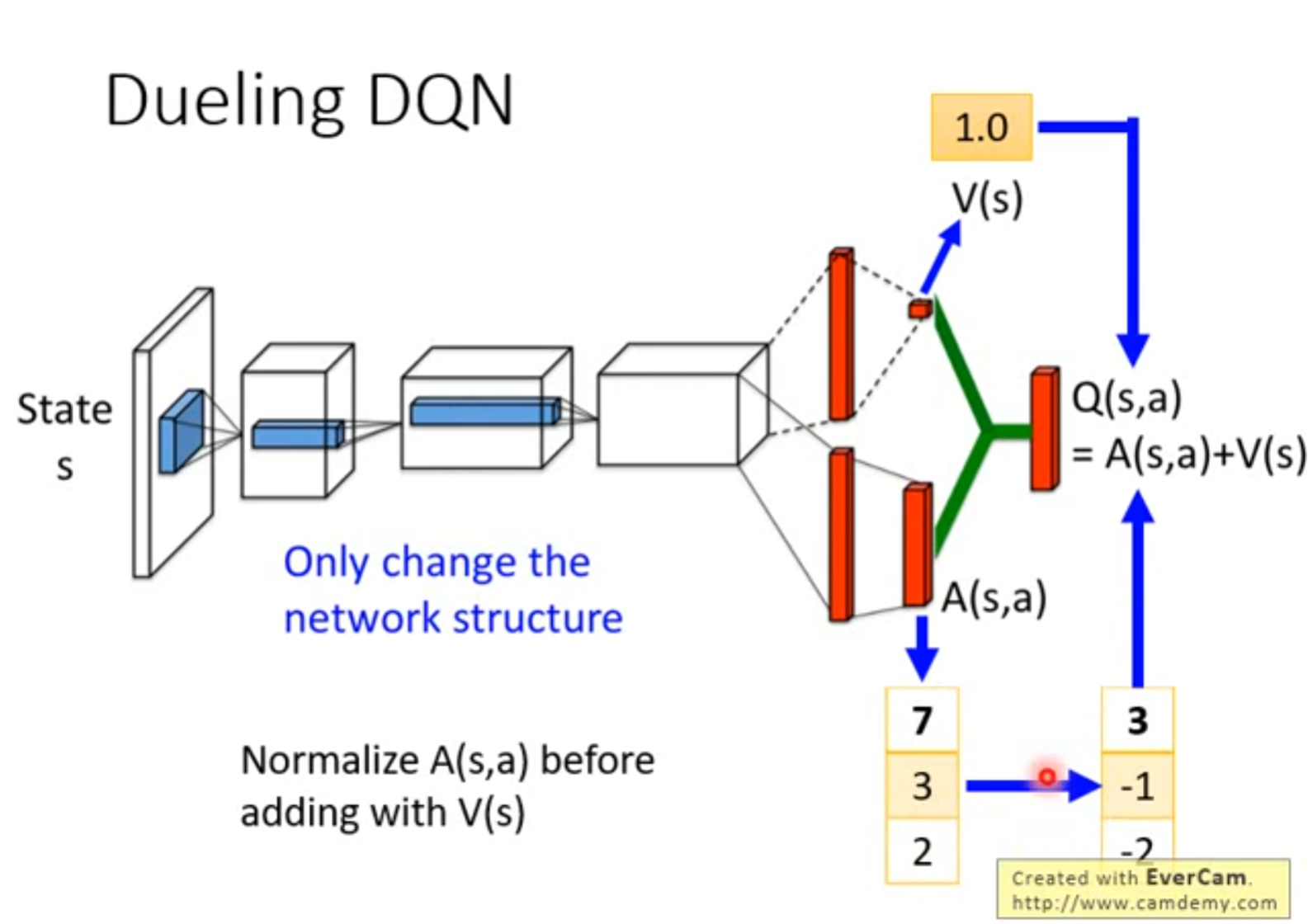
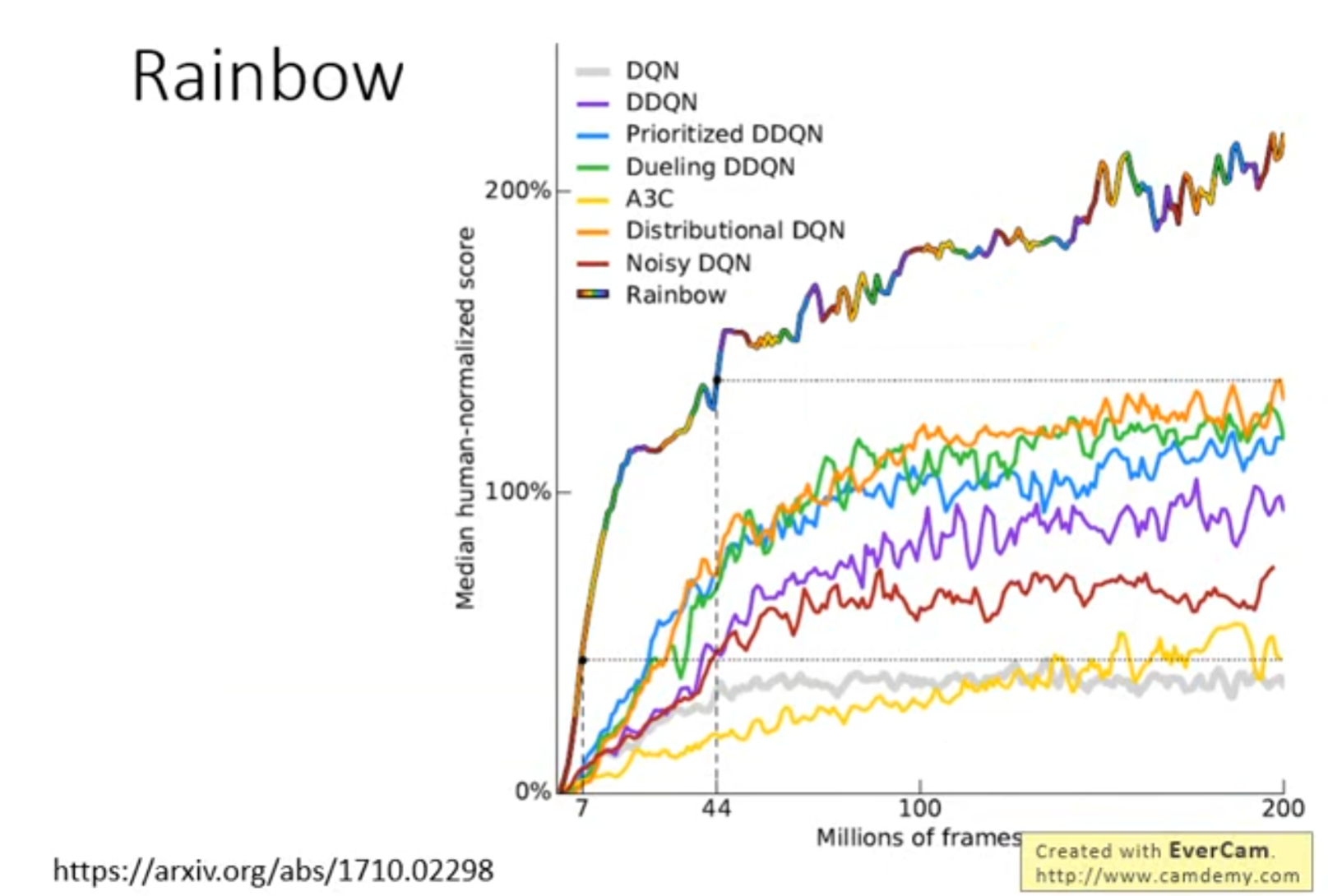
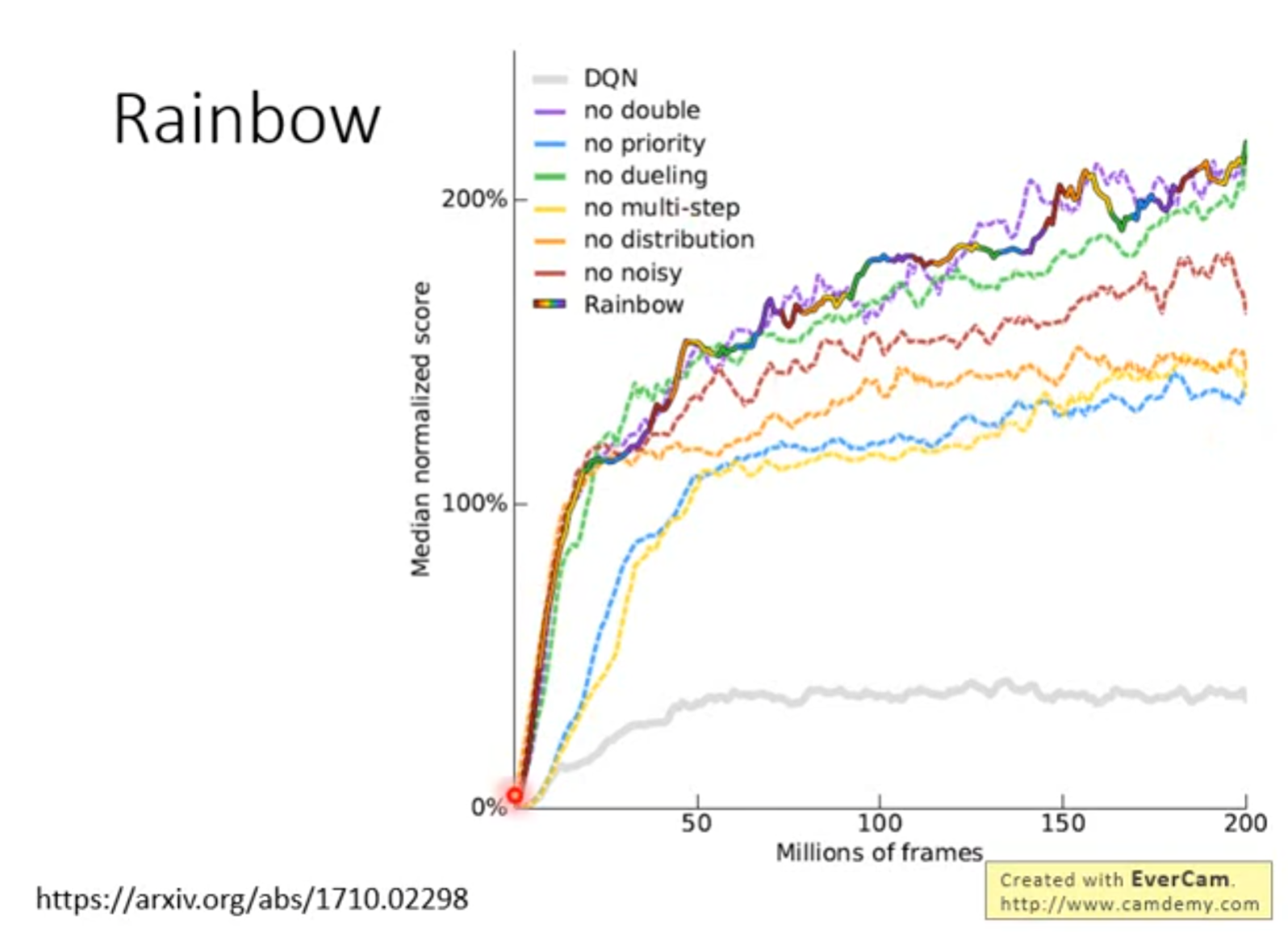
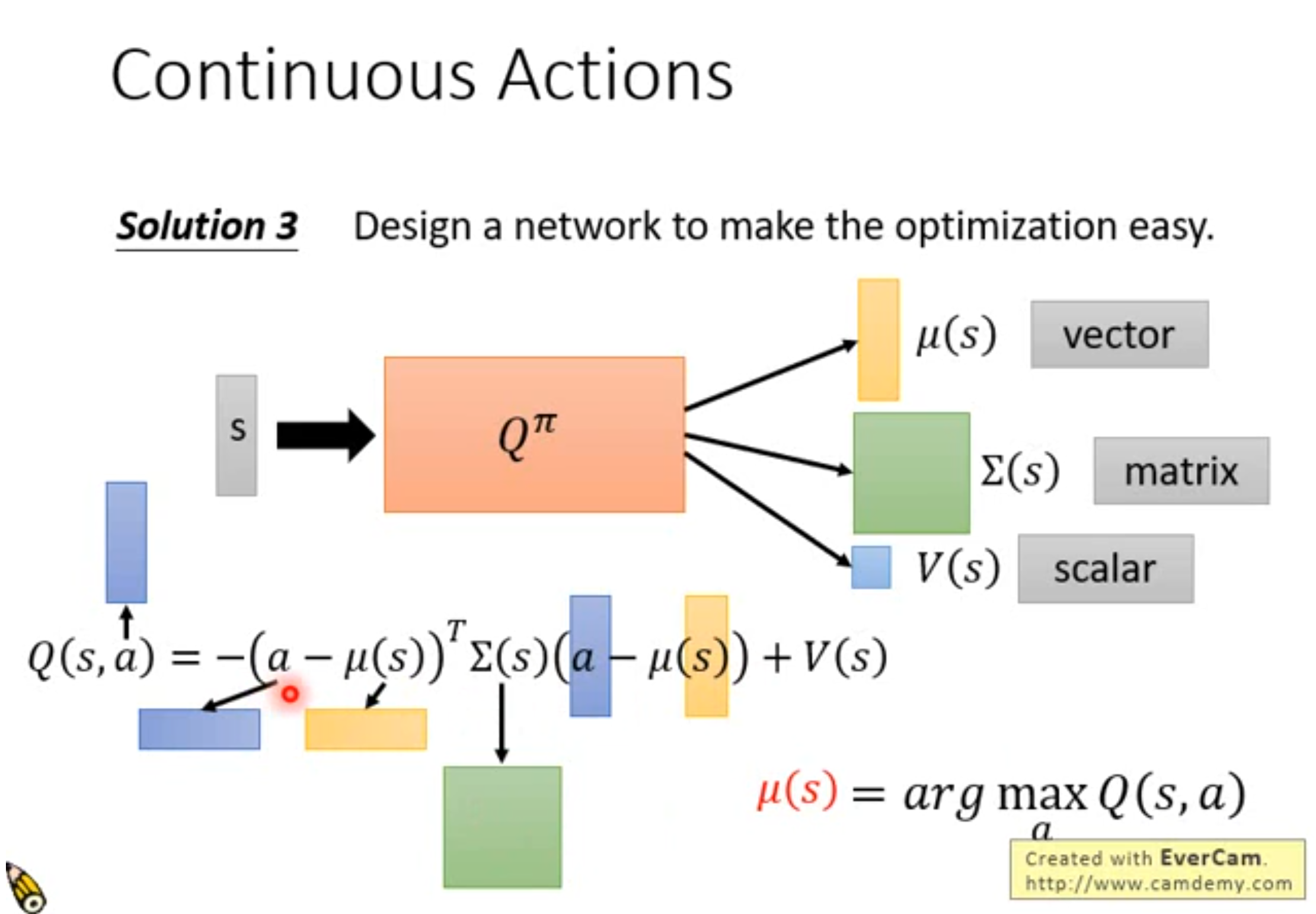
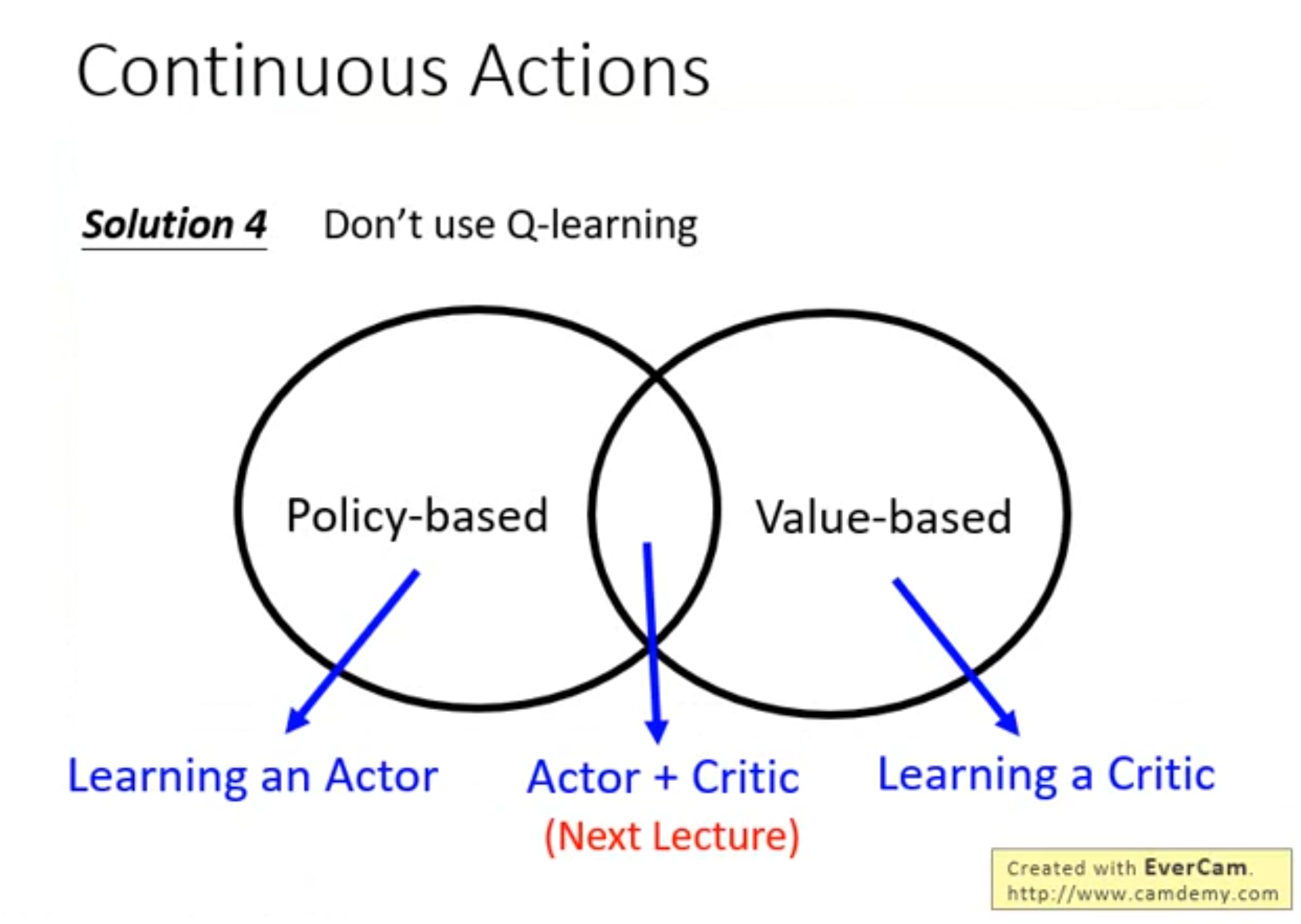
Q-learning